./pages/blog/2026/ai-gemma4-qat.md
2026-06-07
llama-bench -hf unsloth/gemma-4-31B-it-GGUF:IQ4_XS -hf unsloth/gemma-4-31B-it-GGUF:Q4_0 -hf unsloth/gemma-4-31B-it-GGUF:Q4_1 -hf unsloth/gemma-4-31B-it-qat-GGUF:UD-Q4_K_XL --split-mode tensor -n 512 -d 8192,32768,65536,131072
ai@ai:~$ llama-bench -hf unsloth/gemma-4-31B-it-qat-GGUF:UD-Q4_K_XL -n 512 -d 8192,32768,65536,131072 ggml_cuda_init: found 2 CUDA devices (Total VRAM: 31699 MiB): Device 0: NVIDIA GeForce RTX 5060 Ti, compute capability 12.0, VMM: yes, VRAM: 15849 MiB Device 1: NVIDIA GeForce RTX 5060 Ti, compute capability 12.0, VMM: yes, VRAM: 15849 MiB
| model | size | params | backend | ngl | test | t/s |
|---|---|---|---|---|---|---|
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | pp512 @ d8192 | 827.57 ± 4.16 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | tg512 @ d8192 | 20.89 ± 0.00 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | pp512 @ d32768 | 552.09 ± 1.33 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | tg512 @ d32768 | 18.94 ± 0.00 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | pp512 @ d65536 | 382.28 ± 0.64 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | tg512 @ d65536 | 17.25 ± 0.00 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | pp512 @ d131072 | 236.46 ± 0.21 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | tg512 @ d131072 | 13.95 ± 0.00 |
llama-bench -hf unsloth/gemma-4-31B-it-qat-GGUF:UD-Q4_K_XL --split-mode tensor -n 512 -d 8192,32768,65536,131072
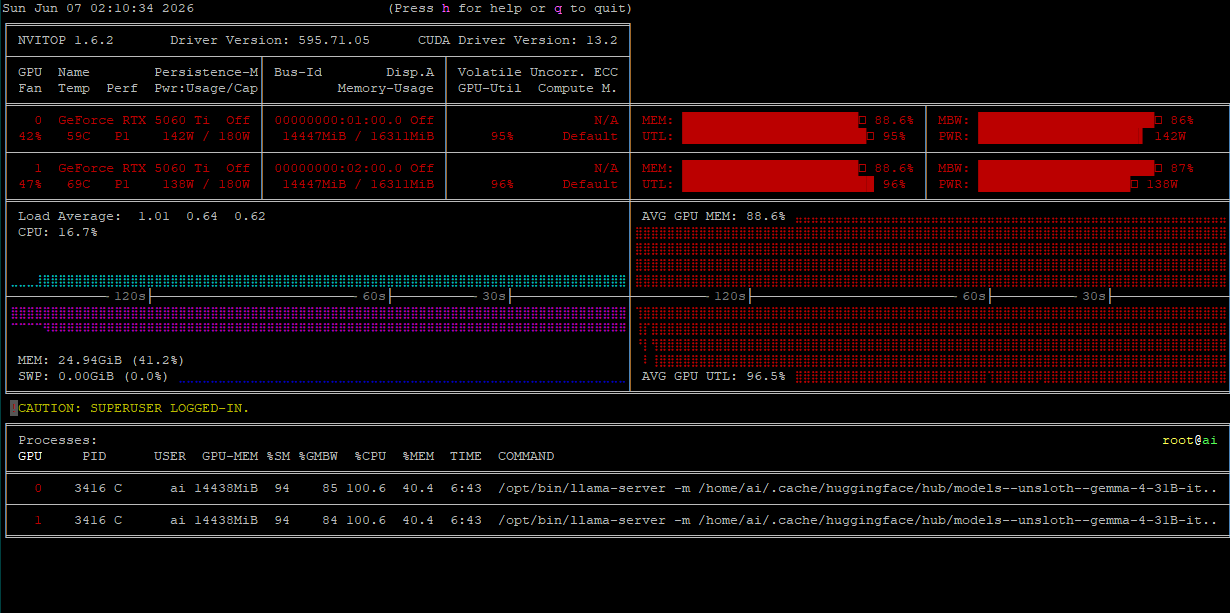
| model | size | params | backend | ngl | sm | test | t/s |
|---|---|---|---|---|---|---|---|
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | tensor | pp512 @ d8192 | 973.03 ± 18.59 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | tensor | tg512 @ d8192 | 36.12 ± 0.06 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | tensor | pp512 @ d32768 | 769.23 ± 12.14 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | tensor | tg512 @ d32768 | 32.98 ± 0.04 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | tensor | pp512 @ d65536 | 603.22 ± 7.29 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | tensor | tg512 @ d65536 | 30.44 ± 0.04 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | tensor | pp512 @ d131072 | 420.75 ± 3.54 |
| gemma4 31B Q4_0 | 16.09 GiB | 30.70 B | CUDA | -1 | tensor | tg512 @ d131072 | 25.11 ± 0.03 |